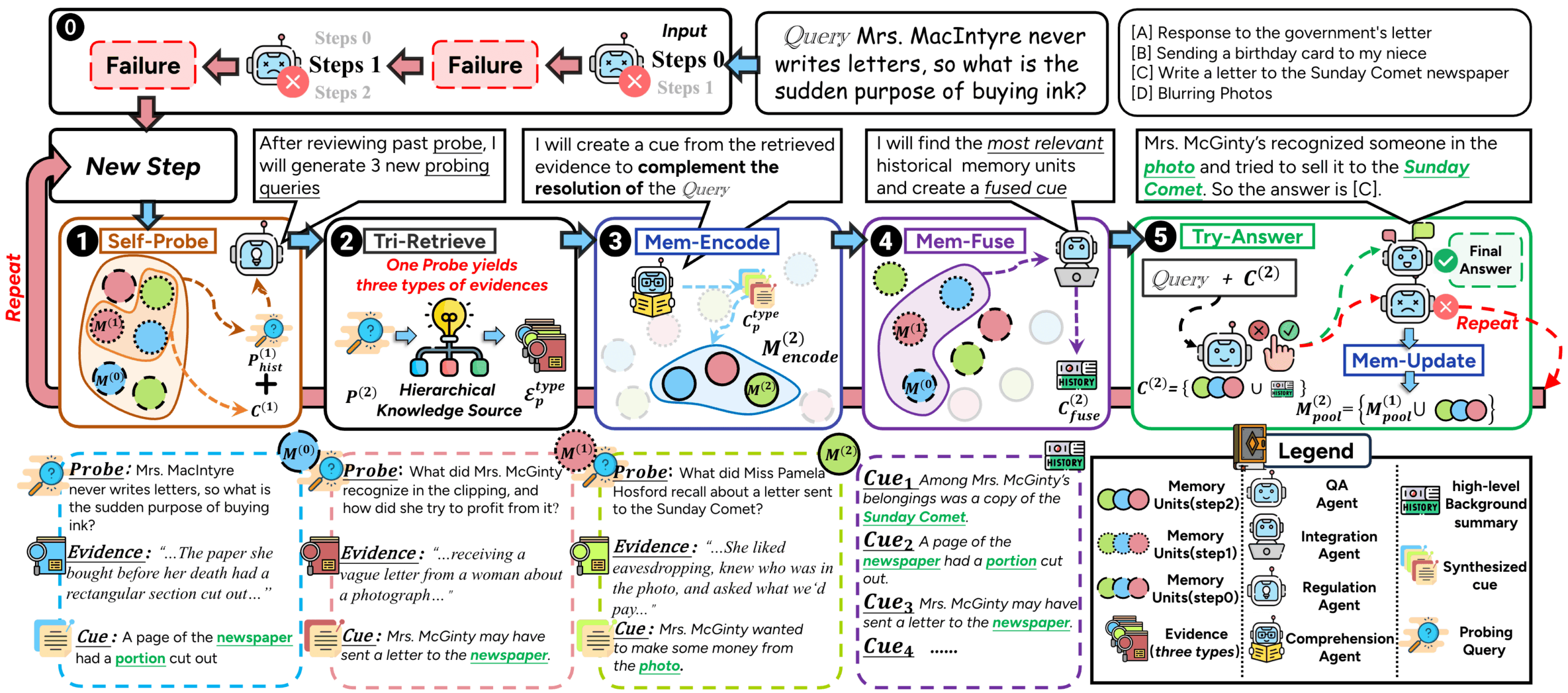
Cursor Memory
综合介绍
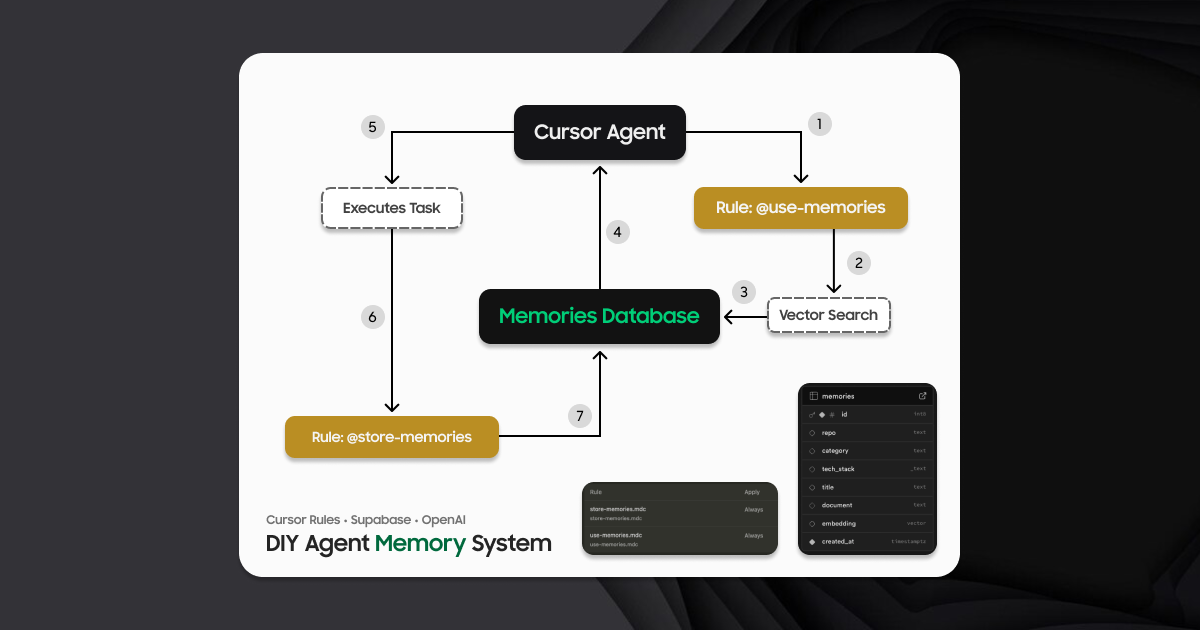
Cursor Memories 是一个命令行(CLI)工具,它为开发者提供了一个强大且持久的外部“记忆”系统。这个工具的核心功能是解决AI编程助手无法长期记忆有价值的开发经验、代码模式和解决方案的问题。它通过连接开发者自己的Supabase云数据库和OpenAI的向量模型,将重要的开发见解结构化地存储起来。当开发者在Cursor编辑器中工作时,AI助手可以通过该工具进行语义化搜索,用自然语言查询并找回相关的历史记录。这使得AI能够基于项目和开发者个人的经验积累,提供更具上下文感知能力和针对性的编程辅助,相当于为每个开发者创建了一个私有、可随时查阅的云端开发知识库。
功能列表
- 云端记忆存储: 将开发过程中的灵感、解决方案和代码模式安全地存储在自己的Supabase数据库中。
- 语义化搜索: 利用OpenAI embeddings技术,可以通过自然语言(而非精确的关键词)来查询和匹配相关的记忆。
- 结构化分类: 允许通过仓库、技术栈、分类(如架构、数据库、安全等)等多个维度来组织和标记每一条记忆。
- 项目隔离: 能够按代码仓库(Repository)组织记忆,让AI在不同项目中可以调取高度相关的历史经验。
- 安全私密: 所有数据都存储在用户自己的Supabase项目里,确保了开发知识的私密性和安全性。
- 高效命令行: 提供简洁快速的命令行指令,方便开发者随时添加和搜索记忆。
- 无缝集成: 设计旨在与Cursor编辑器内的AI Agent协同工作,由AI在后台自动调用以存取记忆。
使用帮助
Cursor Memories 将你的开发经验沉淀为一个可搜索的知识库。它的安装和使用需要一些前置配置,主要是设置用于存储记忆的云端数据库。以下是完整详细的配置和使用流程。
第一步:前置准备 (配置Supabase数据库)
在使用此工具前,你需要在Supabase平台上创建一个免费的云数据库项目。
- 创建Supabase项目
- 访问 supabase.com 并登录。
- 创建一个新的组织(Organization),选择免费套餐。
- 在组织内创建一个新项目(New project),为其命名,设置一个安全的数据库密码,并选择一个服务器区域。项目创建过程大约需要2-3分钟。
- 启用Vector向量扩展
- 项目创建成功后,在左侧导航栏进入
Database->Extensions。 - 在搜索框中找到
vector并启用它。这个扩展是实现语义化搜索的核心。
- 项目创建成功后,在左侧导航栏进入
- 创建
memories数据表- 在左侧导航栏进入
SQL Editor,点击New query。 - 将下面的SQL代码粘贴进去并执行,以创建用于存储记忆的数据表:
CREATE TABLE memories ( id SERIAL PRIMARY KEY, repo TEXT NOT NULL, category TEXT NOT NULL, tech_stack TEXT[] DEFAULT '{}', title TEXT NOT NULL, document TEXT NOT NULL, embedding VECTOR(1536), created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW() );
- 在左侧导航栏进入
- 为向量搜索创建索引
- 再次新建一个查询,将下面的SQL代码粘贴进去并执行。这会为向量搜索创建索引,大幅提升查询速度。
CREATE INDEX ON memories USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
- 再次新建一个查询,将下面的SQL代码粘贴进去并执行。这会为向量搜索创建索引,大幅提升查询速度。
- 创建搜索函数 (RPC)
- 继续新建一个查询,将下面的SQL代码粘贴进去并执行。这将创建一个名为
search_memories的函数,让搜索操作更高效、更安全。CREATE OR REPLACE FUNCTION search_memories( query_embedding VECTOR(1536), match_threshold DOUBLE PRECISION, match_count INTEGER, filter_repo TEXT, filter_category TEXT, filter_tech_stack TEXT[] ) RETURNS TABLE ( id bigint, repo text, category text, tech_stack text[], title text, document text, embedding vector, created_at timestamp with time zone ) LANGUAGE plpgsql AS $$ BEGIN RETURN QUERY SELECT memories.id, memories.repo, memories.category, memories.tech_stack, memories.title, memories.document, memories.embedding, memories.created_at FROM memories WHERE (filter_repo IS NULL OR memories.repo = filter_repo) AND (filter_category IS NULL OR memories.category = filter_category) AND (filter_tech_stack IS NULL OR memories.tech_stack @> filter_tech_stack) AND (1 - (memories.embedding <=> query_embedding)) > match_threshold ORDER BY (memories.embedding <=> query_embedding) LIMIT match_count; END; $$;
- 继续新建一个查询,将下面的SQL代码粘贴进去并执行。这将创建一个名为
- 获取API凭证
- 在左侧导航栏进入
Settings->API。 - 在页面中找到并复制你的 Project URL 和 Service Role Key。同时,你还需要准备好你的 OpenAI API Key。
- 注意:
Service Role Key是高度机密的凭证,请妥善保管,不要泄露。
- 在左侧导航栏进入
第二步:安装与配置
- 全局安装CLI工具在你的终端(命令行工具)中运行以下命令:
npm install -g cursor-memories - 配置环境变量运行以下命令,工具会引导你输入上一步获取的凭证:
memories setup根据提示,依次输入你的Supabase项目URL、Supabase Service Role Key和OpenAI API Key。这些信息将被保存在工具的全局目录中,让你可以在任何项目中直接调用
memories命令。
第三步:如何使用
配置完成后,你就可以通过命令行来管理你的开发记忆了。
添加一条记忆 (memories add)
使用此命令来存储一条新的开发经验。基础语法:memories add --repo="仓库名" --category="分类" --tech_stack="技术,栈" --title="标题" --document="详细内容"
参数说明:
--repo,-r: 记忆所属的代码仓库名称。--category,-c: 记忆的分类,官方推荐分类包括Architecture,Database,Security,Performance,Patterns等。--tech_stack: 使用到的技术栈,用逗号分隔,例如"React,Node.js"。--title,-t: 记忆的简短标题。--document,-d: 记忆的详细内容。如果内容中需要换行,请使用__NEWLINE__代替。
示例: 存储一个数据库连接池的优化方案。
memories add \
--repo="ecommerce-app" \
--category="Database" \
--tech_stack="PostgreSQL,Node.js" \
--title="数据库连接池模式" \
--document="使用 pg-pool 实现连接池以处理高并发数据库连接。配置为 max: 20, idleTimeoutMillis: 30000。这次优化使连接开销减少了60%,响应时间提升了40%。"
搜索记忆 (memories search)
使用此命令通过自然语言查询已存储的记忆。
基础语法:memories search --query="你的问题或关键词" [可选过滤条件]
参数说明:
--query,-q: 你的搜索内容,可以是问题或几个关键词。--repo,-r: (可选) 按仓库名称过滤。--category,-c: (可选) 按分类过滤。--tech_stack,-t: (可选) 按技术栈过滤。--threshold: (可选) 相似度阈值,范围0.0到1.0,默认为0.3。--limit: (可选) 最大返回结果数,默认为10。--full: (可选) 显示匹配结果的完整详细信息。
示例: 搜索关于性能优化的记忆。
memories search --query="如何优化数据库性能" --category="Performance" --full
应用场景
- 沉淀解决方案当你解决一个复杂的bug或完成一次巧妙的性能优化后,使用
memories add命令,将问题背景、解决方案和关键代码记录下来。未来当自己或同事遇到类似问题时,只需用自然语言搜索memories search --query="修复那个图片上传的超时bug",就能立刻找到当时的解决方案。 - 统一团队规范团队的技术负责人可以将项目的设计模式、架构决策、代码规范等作为
Architecture或Patterns类别的记忆存入团队共享的Supabase项目中。新成员入职后,AI助手就能基于这些“权威记忆”给出符合团队规范的建议,加速其融入过程。 - 跨项目知识复用你在A项目中实现了一个通用的身份验证模块。你可以将其核心思想存入记忆库,并标记
tech_stack为JWT,Node.js。几个月后,在B项目中需要类似功能时,可以搜索memories search --query="用户认证流程",快速回忆并复用之前的成熟方案。 - 辅助代码审查 (Code Review)在进行代码审查时,如果发现某个实现方案有更优的模式,审查者可以将更优方案添加为一条记忆。然后,在评论中建议代码作者可以搜索
memories search --query="异步任务处理模式"来查看更佳实践,这比单纯的文字描述更具说服力。
QA
- 这个工具和普通笔记软件有什么区别?最大的区别在于语义化搜索。普通笔记依赖精确的关键词匹配,而Cursor Memories利用AI模型将你的笔记和查询都转化为向量,通过计算向量间的相似度来查找内容。这意味着你可以用“数据库很卡怎么办”来找到标题为“优化SQL查询性能”的笔记,搜索更智能、更符合人类思维。
- 我的开发笔记是私密的吗?是的。所有数据都存储在你个人创建和控制的Supabase项目中。本工具的开发者和任何第三方都无法访问你的数据。安全性由Supabase平台保障。
- 我能为不同的客户或项目建立独立的记忆库吗?该工具的全局安装模式默认连接到一个Supabase项目。如果你需要为不同项目或客户维护完全隔离的记忆库,官方建议采取本地克隆的方案:将项目
git clone到本地,为每个需要隔离的项目单独运行npm link和memories setup,配置不同的Supabase数据库凭证。 - 使用这个工具必须要有OpenAI API Key吗?是的,必须要有。核心的语义化搜索功能依赖OpenAI的
embeddings模型来将文本转换成向量。没有API Key,工具将无法实现其最关键的搜索能力。